本文共 4241 字,大约阅读时间需要 14 分钟。
第一部分
(1)单指令单数据(SISD)与单指令多数据(SIMD)的区别?
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。
(2)GPU中的warp与thread?
单个顶点,像素或片元等元素的计算通过thread来完成,和CPU中的thread不同,GPU中的thread包含一些内存,用于存放输入数据和着色器执行所需的寄存器空间。多个使用同一着色器程序的thread成组执行后则被称为warp(NVIDIA叫法,在AMD中为wavefronts)。(3)warp读取内存时执行的操作?
当一个warp需要内存读取时,warp中所有的thread都会停止,因为它们执行的是相同的指令。读取内存就意味着该warp拥塞,正在等待它的结果。这时系统会切换到另一个warp继续执行。因为两个warp之间没有数据交互,所以切换到另外一个warp中并不会消耗时间。(4)影响SIMD执行效率的几个因素?
第一个因素是着色器程序结构,由于寄存器总量是有限的,那么一个着色程序的thread所需要的寄存器的数量越多,那么threads的数量越少,进而导致留在GPU中warp的数量也会越少。过少的warp意味着当发生拥塞时,GPU中可能不再存在空闲的warp,也就不能靠切换warp(switch)来减轻问题。另外一个因素是动态分支,由于每个warp执行的指令都是相同的,如果该warp的所有thread执行相同的分支,那么warp就不需要考虑其他分支,如果有一个thread执行了不同分支,那么整个warp中所有其他thread都需要遍历这些分支。
(5)渲染管线各阶段的可编程程度?
渲染管线中可编程的部分为顶点着色器,细分,几何着色器与片元着色器(Piexl Shader)。细分和几何着色器为可选编程,并非所有GPU都支持这两部分,比如移动设备。可以设定状态的部分为屏幕映射和merge,完全不可编程的部分为裁剪与光栅化。后续可以送到光栅化阶段,或者完全不进行后续的光栅化,而是将其作为一个非图形的stream processor。处理后的数据可以被再次送回到管线中,这种操作对流体模拟或其他粒子效果很有用。
(5)stream output阶段的作用? 在顶点处理阶段之后,可以选择将输出的顶点以有序数组的方式送到stream中。后续Stream output 阶段让GPU可以当做几何引擎使用,该阶段可以将数据出处到数组中,供CPU使用,也可以接着给GPU使用。这个阶段可以用来做物理模拟。stream out返回的数据只是浮点形式,所以应注意一下它的内存消耗。由于stream out作用于三角形图元上,而非顶点,所以原始网格的拓扑关系都会消失。因此,我们送往渲染管线的数据都是点集。在OpenGL中,stream out阶段被称作transform feedback。输出的图元数据顺序和输入的顺序是保证相同的。
(6)如何避免数据的race condition?
数据的race condition就是多个着色程序都竞争地想去影响一些值,导致了结果的不确定。GPU通过某个着色器独有的原子单元来避免该问题,不过原子同样意味着另外一个着色器访问一个正在被修改的内存时发生了拥塞。(7)简述ROVs(Rasterizer order views)?
ROVs在DX11.3引入,它指定了程序执行的顺序,不论片元着色器计算出结果的顺序是怎么样的,ROVs都会将结果按三角形输入顺序排序送到merge stage。这有利于半透明物体的渲染。ROVs和UAVs很像,不过ROVs指定了数据被访问的顺序。ROVs使开发者可以定义自己的blend 方法,因为ROVs的任何地方都是可以被访问和修改的,这样也不需要merge阶段了。ROVs的代价就是,如果遇到一个无序的访问,那么pixel shader可能会一直拥塞到当前顺序前的所有调用执行完成。(8)early-z算法?
假如片元着色器(Piexl Shader)计算出fragment后发现这个fragment无法通过z-test,那么所有在片元着色器中的计算都是无效的。为了避免这种浪费,许多GPU会在片元着色器执行前进行提前深度测试。第二部分
SIMD
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算
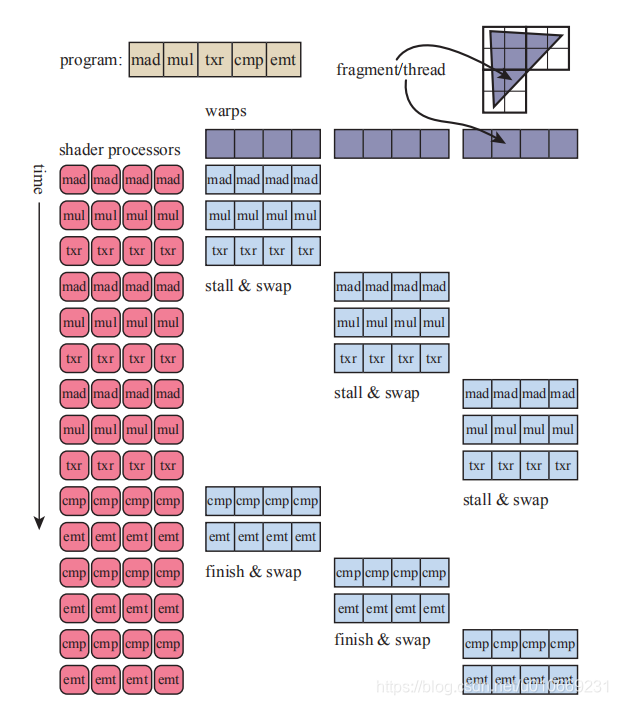
当一个warp需要内存读取时,warp中所有的thread都会停止,因为它们执行的是相同的指令。读取内存就意味着该warp拥塞,正在等待它的结果。这时系统会切换到另一个warp继续执行。因为两个warp之间没有数据交互,所以切换到另外一个warp中并不会消耗时间。
着色器程序的结构是影响效率的重要因素。由于寄存器总量是有限的,那么一个着色程序的thread所需要的寄存器的数量越多,那么threads的数量越少,进而导致留在GPU中warp的数量也会越少。过少的warp意味着当发生拥塞时,GPU中可能不再存在空闲的warp,也就不能靠切换warp(switch)来减轻问题。
另外一个因素是动态分支,由于每个warp执行的指令都是相同的,如果该warp的所有thread执行相同的分支,那么warp就不需要考虑其他分支,如果有一个thread执行了不同分支,那么整个warp中所有其他thread都需要遍历这些分支。这种问题被称作thread divergence。
渲染管线的GPU实现,以及可编程程度?
按顺序分别为:
顶点着色器 细分 几何着色器 Clipping Screen mapping 光栅化:Triangle Set up&Triangle Traversal pixel Shader merge渲染管线中可编程的部分为顶点着色器,细分,几何着色器与片元着色器(Piexl Shader)。细分和几何着色器为可选编程,并非所有GPU都支持这两部分,比如移动设备。
可以设定状态的部分为屏幕映射和merge,完全不可编程的部分为裁剪与光栅化。
着色器虚拟机

底层的virtual machine为不同类型的输入和输出提供了不同的寄存器。uniform inputs的constant register的数量比varying input的registers多,这是由于varying的输入和输出需要单独地存储在每个Piexl或Vertex中,这天然的限制了它们需要的寄存器的数量。uniform输入被存储一次,然后在整个draw call中被piexl和vertex使用。
virtual machine为临时空间提供了通用的temporary registers。所有类型的寄存器都可以在临时寄存器中使用整数值进行数组索引。Tessellation Stage的三个部分?
DX中被称作 hull shader,tessllator shader,domain shader
OpenGl中被称作 tessellation control shader,primitive generator ,tessellation evaluation shader
一个三角形外的三个邻接顶点和一条直线的两个邻接顶点可以被输入到几何着色器中,如上图右边
简述MRT(Multiple render targets)?
如简单的将pixel shader的结果输出到color buffer和z-buffer中不同,MRT可以为每个fragment生成多组数值并存储在不同的buffer中,每个buffer都被称作render target。
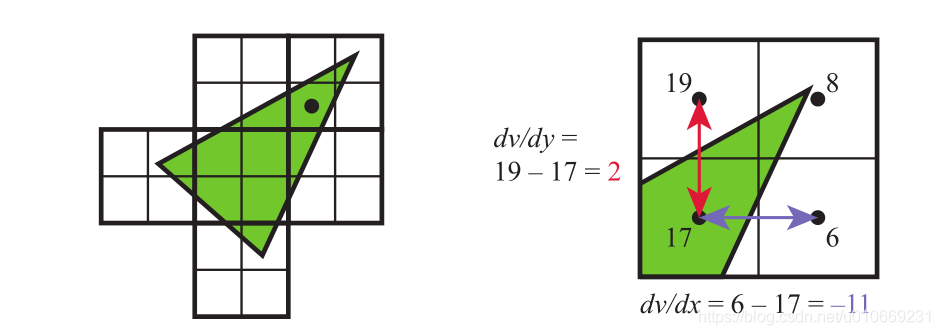
一般情况下在Pixel shader中是不能访问或影响相邻pixel的结果。特例之一就是在计算梯度或微分的时候pixel Shader可以直接访问邻接的fragment。计算出的梯度对一些操作比如Texture filtering很重要,因为我们需要知道一张图像覆盖了多少像素。
所有的现代GPU都是通过将fragments组成一个2x2的quad来实现这个feature,这也说明了为什么GPU喜欢按quad来调度。当Piexl shader需要梯度值的时候,就会返回邻接fragment的difference。
一个unified core有能力去访问相邻的数据,通过将不同的thread放在相同的warps中。这样做的后果之一就是不能在被dynamic flow control影响的部分使用,比如 if和循环的部分。一组内的所有fragment必须采用同一系列指令才能使四个piexl计算梯度的结果有意义。
DX11引入了一个新的缓冲类型称为unordered acess view(UAV),在起初UAV只能在piexl和geometry shader中使用,在DX11.1中拓展到了所有shader。在OpenGL中被称作 shader storage buffer object(SSBO)。Piexl shader以无序方式并行执行,而这个storage buffer在它们中被共享。
转载地址:http://jfuh.baihongyu.com/